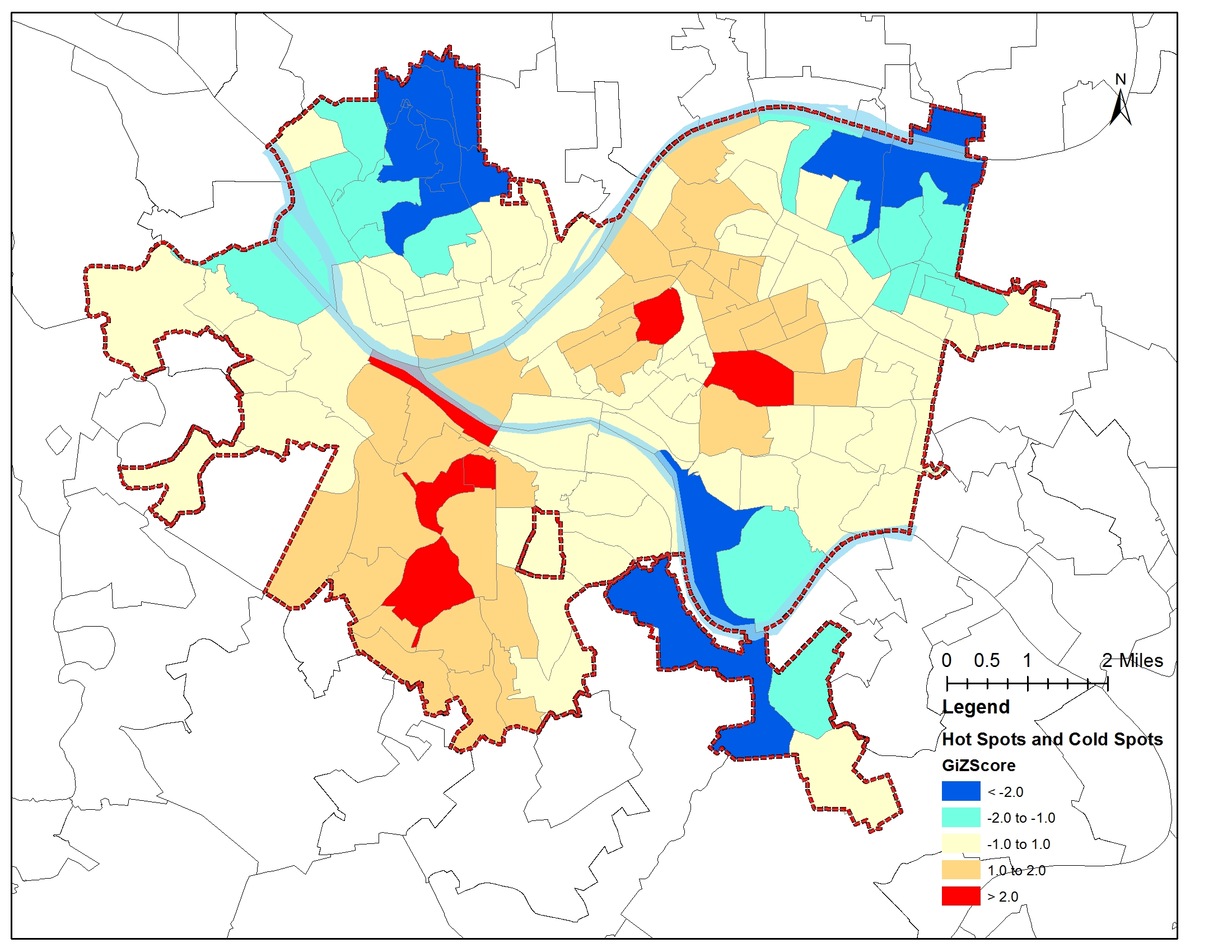
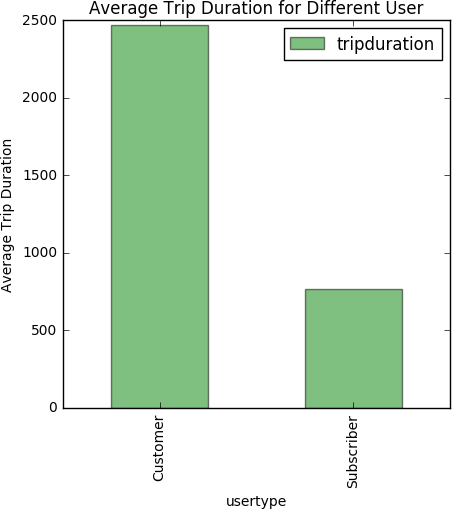
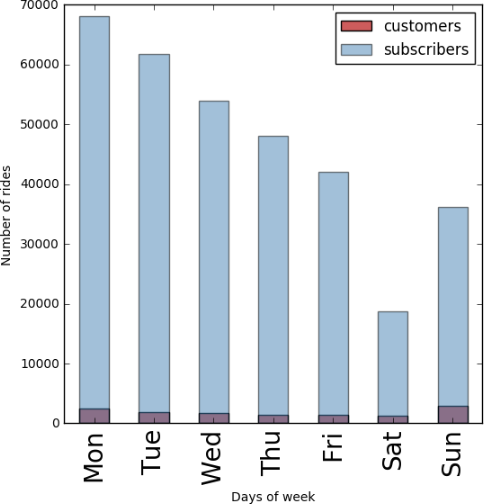
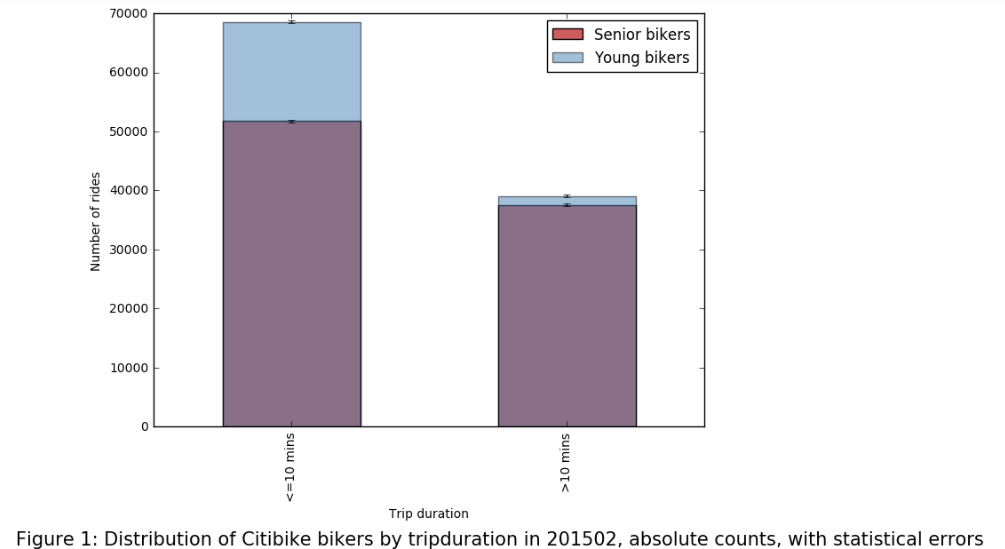
AbstractThis report is based on my PUI Assignment 2 on Homework3 about a Citibike analysis with the python tool. The goal is to explore the Citibike trip duration difference between one-time customers and subscribers in terms of the MTP (Mean Trip Duration). The idea is that to prove that the average trip duration of single time customers is more than that of the subscribers, and further concludes that a single time customer would make better maximize the utilization than a subscriber. A hypothesis is established below. As the samples are not equal, a further Two-sided T-test is implemented, the results support the hypothesis.Keywords: CitiBike Data, Data Wrangling, Null Hypothesis, Alternative Hypothesis, Statistical Significance Level, Two-sided t-testHypothesis Null HypothesisH0: T(customer) <= T(subscriber)The mean trip duration of single time customers over a week is less than or equal to the mean trip duration of the subscribers over a week Alternative HypothesisH1: T(customer) > T(subscriber)The mean trip duration of single time customers over a week is more than the mean trip duration of the subscribers over a week. Statistical Significance LevelSignificance level: α = 0.05A significance level alpha(α) is chosen here to reflect how significant the hypothesis testing will be at the end of the test. Data AnalysisThe data was collected from the CitiBike_Data_Website for the trip duration from both one-time customer and subscriber. Later, this data was used to clean, organize, select, analyze, plot and visualize. First, the Null and Alternative hypothesis were established with a statistical significance level at 0.05, and then the data was collected, tabulated, cleaned, and reshaped.The analysis is conducted by applying Pandas and DataFrames to the Python to get the mean trip duration for Customers(one-time user) and Subscribers respectively. The figures are plotted by using Matplotlib accordingly. Meanwhile, as t-test applies for testing the difference between the samples when the variances of two normal distributions are unknown, which fit in the situation, the distribution of data is subjected to a two-sided t-test.