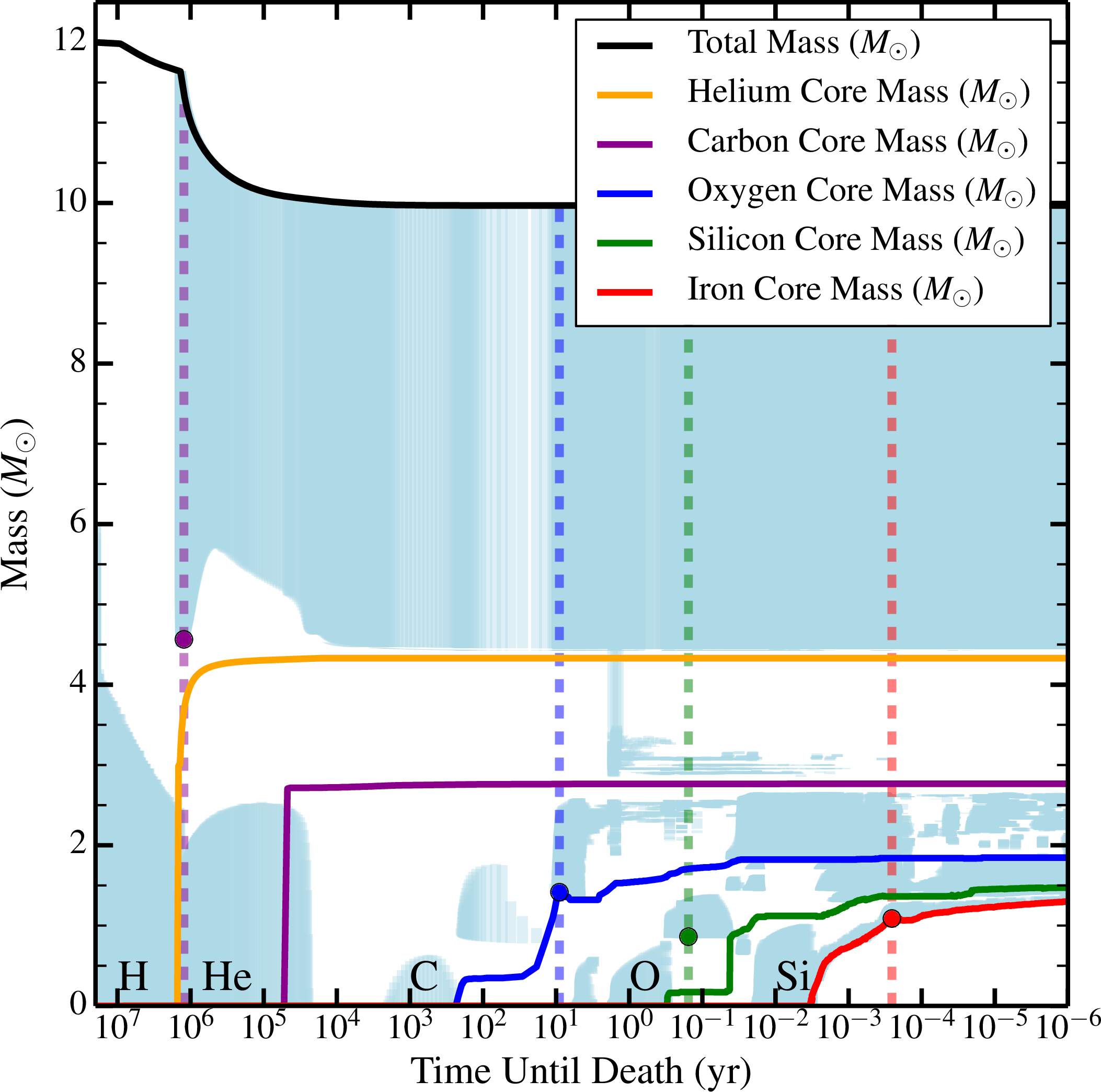
The core rotation rates of massive stars have a substantial impact on the nature of core collapse supernovae and their compact remnants. We demonstrate that internal gravity waves (IGW), excited via envelope convection during a red supergiant phase or during vigorous late time burning phases, can have a significant impact on the rotation rate of the pre-SN core. In typical (10 M⊙ ≲ M ≲ 20 M⊙) supernova progenitors, IGW may substantially spin down the core, leading to iron core rotation periods $P_{\rm min,Fe} \gtrsim 50 \, {\rm s}$. Angular momentum (AM) conservation during the supernova would entail minimum NS rotation periods of $P_{\rm min,NS} \gtrsim 3 \, {\rm ms}$. In most cases, the combined effects of magnetic torques and IGW AM transport likely lead to substantially longer rotation periods. However, the stochastic influx of AM delivered by IGW during shell burning phases inevitably spin up a slowly rotating stellar core, leading to a maximum possible core rotation period. We estimate maximum iron core rotation periods of $P_{\rm max,Fe} \lesssim 10^4 \, {\rm s}$ in typical core collapse supernova progenitors, and a corresponding spin period of $P_{\rm max, NS} \lesssim 400 \, {\rm ms}$ for newborn neutron stars. This is comparable to the typical birth spin periods of most radio pulsars. Stochastic spin-up via IGW during shell O/Si burning may thus determine the initial rotation rate of most neutron stars. For a given progenitor, this theory predicts a Maxwellian distribution in pre-collapse core rotation frequency that is uncorrelated with the spin of the overlying envelope.