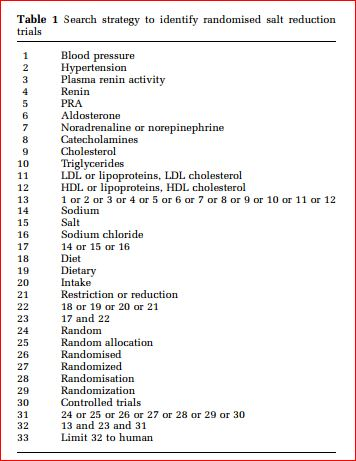
Concepts of Meta AnalysesWe face evidence based information and published primary research every day; while this lets us access a wealth of health information, as consumers and health care practitioners, we also have to deal with studies on health care interventions and risks that frequently contradict each other: besides, given this glut of information, we can find it overwhelming as to what should be our basis of decision making. As a result, unless we can resolve this diversity and plethora of information, we can be drowned in the information deluge and end up making wrong decisions. We can tide over if we can closely examine the studies and derive summary estimates to guide our assessments; this we can obtain using a meta analysis. Meta analysis refers to a process where we integrate the results of many studies to arrive at an evidence synthesis \cite{normand1999tutorial} . This evidence synthesis is a form of systematic review; however, in addition to narrative summary that is characteristic of systematic review, in meta analysis, we numerically pool the results of the studies and arrive at a summary estimate. The purpose of this paper is to describe how to conduct a meta analysis. We will describe the processes of framing a question, obtaining studies, assessing their heterogeneity, obtaining summary estimates, assessment of publication bias, and analysis of subgroups of data from the sets of studies in R with an example of a study.Nine Steps to Meta AnalysesThe following nine steps are part of meta analyses.Frame a question (based on a theory)Run a search (on Pubmed/Medline, Google Scholar, other sources)Read the abstract and title of the individual papers.Abstract information from the selected set of final articles.Determine the quality of the information in these articles. This is done using a judgment of their internal validity but also using the GRADE criteriaDetermine the extent to which these articles are heterogeneousEstimate the summary effect size in the form of Odds Ratio and using both fixed and random effects models and construct a forest plotDetermine the extent to which these articles have publication bias and run a funnel plotConduct subgroup analyses and meta regression to test if there are subsets of research that capture the summary effectsStep I: Frame a QuestionFor framing an answerable question in a meta analysis, use the PICO framework \cite{schardt2007utilization}. PICO is an acronym for ”Participant-Intervention-Comparator-Outcomes”. "Participant" here refers to the individuals or population who will be studied and whose profiles are of interest to the analyst. For example, if we are interested to study the effectiveness of a drug such as nedocromil on bronchoconstriction (narrowing of air passages) among adult asthma patients, then we shall include only adult asthmatics for our study, not children or older adults (if such individuals are not of our interest); if we are interested to study the effectiveness of mindfulness meditation for anxiety for adults, then again adult age group would be our interest; we could further narrow down the age band to our interest.Intervention too, needs to be as broadly or as narrowly defined keeping only the interventions of our interest. Usually, meta analyses are done in assimilating studies that are RCTs or quasi-experimental studies where pairs of interventions (intervention versus placebo or interventions versus conventional treatment or interventions and no treatment) are compared \cite{normand1999tutorial}. However, meta analyses are not necessarily restricted only to randomised controlled trials, these are now increasingly applied to observational study designs as well for example cohort and case control studies; in these situations, we refer to the specific expsoure variables of our interest \cite{stroup2000meta} . Meta-analyses are also conducted for diagnostic and screening studies \cite{hasselblad1995meta}.Let's say we are interested to study if consumption of plant based diets is associated with reduced risk of cardiovascular illnesses and myocardial infarction. You can see that for ethical reasons, it is not possible to conduct randomised controlled trials so that one group will be forced to consume plant based diet and the other group will be forced to consume non-plant based diet, but it is possible to obtain that information about heart diseases from two groups of people who have consumed and not consumed certain levels of vegetarian items in their diets. Such studies are observational epidemiological studies and using observational studies such as cohort and case control studies. In such situations, it is useful to summarise findings of cohort and case control studies. Intervention then is not appropriate; however, we use the term ”Exposure”. Likewise, the comparison group is important as well. The comparison group can be ”no intervention”, or ”placebo”, or ”usual treatment”.The outcomes that we are interested can be narrowly or broadly defined based on the objective of the meta analysis. If the outcome is narrowly defined, then the meta analysis is only restricted to that outcome, for instance, if we are interested to study the effectiveness of mindfulness meditation on anxiety then, anxiety is our outcome; we are not interested to find out if mindfulness is effective for depression. On the other hand, if the objective of hte study is to test if mindfulness meditation is useful for ”any health outcome”, then the scope of the search is much wider. So, after you have set up your theory and your question, now is the time to rewrite the question and reframe it as a PICO formatted question. Say we are interested to find out if minduflness meditation is effective for anxiety, then we may state the question in PICO as follows:P: Adults (age 18 years and above), both sexes, all ethnicity, all nationalityI: Mindfulness MeditationC: Placebo, Or No Intervention, or Anxiolytics Or Traditional Approaches, or Drug Based Approaches, or Other Cognitive Behavioural TherapyO: Anxiety Symptom Scores, or Generalised AnxietyThen, on the basis of PICO, we reframe the question as follows: ”Among Adults, compared with all other approaches, what is the effectiveness of Mindfulness Meditation for the relief of Anxiety?”Step II: Conduct a Search of the Literature DatabasesAfter you have decided the PICO, you will conduct a search of the literature databases. This will help you to identify the appropriate search terms. These search terms are arranged using Boolean Logic, fuzzy logic, specific search related controlled vocabulary, symbols of trucation or expansion, and placement of the terms in different sections of a reported study \cite{tuttle2009pubmed} . In Boolean Logic, you use the keywords, ”AND”, ”OR”, and ”NOT” in various combinations to expand or narrow down search results and findings. For example,”Adults” AND ”Mindfulness Meditation” will find only those articles that have BOTH adults AND mindfulness meditation as their subject topics. While,”Adults” OR ”Mindfulness Meditation” will find all articles that have EITHER ”Adults” OR ”Mindfulness Meditation” in their subject topics, so the number of results returned will be larger.”Adults” NOT ”Mindfulness Meditation” will find only those articles that contain ”Adults” but will exclude all articles that have ”Mindfulness Meditation” as their topic area.In addition to the use of Boolean logic, you can also use ”fuzzy logic” to search for specific articles. When you use fuzzy logic, you use search terms where you use words like ”Adults” NEAR ”Mindfulness” or ”Adults” WITHIN 5 Words of ”Mindfulness” to search for articles that are very specific. These can be combined in many different ways.Many databases, such as Pubmed/Medline, contain MeSH (Medical Subject Headings) as controlled vocabulary where hte curators of thse databses maintain or archive difernet articles under specific search terms \cite{robinson2002development} . When you search Medline or Pubmed, you can use MeSH terms to search for your studies. You can use or combine MeSH terms along with other terms to search more widely or more comprehensively.Besides these, you will use specific symbols such as asterisk (*) marks and dollar signs to indicate truncation or find related terms to find out articles. For example, if you use something like ”Meditat$” in a search term, then you can find articles that use the terms ”meditating”, or ”meditation”, or ”meditative” or ”Meditational”; you will find list of such symbols in the documentation section of the database that you intend to search \cite{robinson2002development} .Finally, search terms can occur in many different sections and parts of a study report. One way to search is to search the title and abstract of most studies. Another way to search place to search is within the entire body of the article. Thus, combining these various strategies, you can run a comprehensive search of the publications or research that will contain data that you can use for your meta-analysis.Step III: Select the articles for meta analysis by reading Titles and Abstracts and full textsFirst, read the titles and abstracts of all relevant searched papers. But before you do so, set up a scheme where you will decide that you will select and reject articles for your meta analysis. For example, you can set up a scheme where you can write:The article is irrelevant for the study questionThe article does not have the relevant populationThe article does not have the relevant intervention (or exposure)The article does not have a relevant comparison groupThe article does not discuss the outcome that is of interest to this researchThe article is published in a non-standard format and not suitable for reviewThe article is published in a foreign language and cannot be translatedThe article is published outside of the date rangesThe article is a duplicate of another article (same publication published twice)Use this scheme to go through each and every article you retrieved initially on the basis of reading their titles and abstracts. Usually only one clause is good enough to reject a study and note it that study got rejected on that criterion, and the first clause that rejects the study is noted down as the main cause. So, even if a study can be rejected on two clauses, the first one that rejects the study is mentioned as the main clause of rejection; you will need to put together a process diagram to indicate which articles were rejected and why. Such a process diagram is referred to as PRISMA (Preferred Reporting Items of Systematic Reviews and Meta Analyses) chart \cite{moher2009preferred}. After you have run through this step and have identified a certain number of studies which must be included in the meta-analysis, obtain their full texts. Then read the full text once more and conduct this rejection exercise and note the numbers. As may be expected, you will reject fewer articles in this round. Then, read the full text and hand search the reference lists of these articles to widen your research. This step is critical. Often, in this step, you will find out sources that you must search, or identify authors whose work you must read to get a full list of all works and researches that have been conducted on this topic. Do not skip this step. In this step, you will note that some authors feature prominently, and some research groups surface; take a note of them; you may have to write to a few authors to identify if they have published more research. All this is needed to run a thorough search of the studies so that you will not miss any study that may be relevant for this meta analysis. Step IV: Abstract information from these articlesOnce you know that you have a set of studies that you will work with, you will need to work with, you will now need to abstract data from them for your study. At the minimum, you must obtain the following information for each study included in you analysis:The name of the first authorThe year the article was publishedThe population on whom the study was conductedThe type of research (was it an RCT? Or if observational, what type of study was it?)What was the intervention exactly? (A brief description of the intervention)The comparison condition (what was it compared with?)What was the outcome and how was it measured?How many individuals were in the intervention (Ne)?How many people were included in the control arm (Nc)?If the outcomes were measured in a continuous scale, what was the mean value of the outcome among those in the intervention arm?If the outcome was meausured on a continuous scale, the mean of the outcome among those in the comparison conditionIf the outcome was measured on a continuous scale, what was the standard deviation of the measure for the exposure or intervention?If the outcome was measured on a continuous scale, what was the standard deviation of the measure for the comparison arm?If the outcome was measured on a binary scale (more on this later), the number of people with the outcome in the intervention armIf the outcome was measured on a binary scale, the number of people with the outcome on the comparison armA quality score or a note on the quality or crticial appraisal of each studyThis is just a suggestion; I do not recommend a fixed set of variables and you will determine what variables you need for each meta analysis. If you use a software such as Revman, then that will guide you with the process of abstraction of data from each article and you should follow the steps there. Note that in this case, we are only considering tabulation of these information per article. Also note that in this case, we will work with one intervention and one outcome in each table. You may have more than one outcome in the paper; in that case, you will need to set up different tables. Enter this information on a spreadsheet, and export the spreadsheet in the form of a csv file that you can input into R. In this exercise we will use R for statistical computing \cite{Rcite}Step V: Determine the quality of information of these articlesFor each article, you will need to critically appraise the information contained within it and decide if the publication you are considering for your review meets the internal validity criteria. At the minimum you will need to identify the following:What is the theory and the hypotheses this research is about?Is the sample size adequate for the research question? is this study underpowered?To what extent did the authors eliminate biases in the study? Even if it is an RCT, was there blinding? How confident are you that the authors conducted an appropriate randomisation procedure? What is the likelihood that the groups that were compared were very different with respect to the prognosis? - If this is an RCT, did the authors conduct an intention to treat analysis?If this is an observational study, how did the authors eliminate the risks of selection bias? How much was the risks of information bias from the participants eliminated?What confounding variables were controlled for? Are these confounding variables sufficient? (This will require that you will have to know something about the biology of the relationship; if you are not confident, ask someone)A great way to ascertain the quality of each article (rather each outcome within an article) is to use the GRADE (Grading recommendations assessment, development and evaluation) criteria and use the GRADEpro software to judge the quality of the outcome-intervention pairing.Step VI: Determine the extent to which the articles are heterogeneousThink about the distinction between a systematic review and a meta analysis. A systematic review is one where the analysts follow the same steps as above (frame a question, conduct a search, identify the right type of research, extract information from the articles). Then, in a systematic review but not in a meta analysis, all studies that are fit to be included in the review get summarised and patterns of information are tabulated and itemised. This means, that all study findings for a set of outcomes and interventions are identified, tabulated and discussed in systematic reviews. On the other hand, in a meta analysis, there is an implicit assumption that the studies have come from a population that is fairly uniform across the intervention and outcomes. This may indicate one of the two issues: either that the body of the studies that you have identified are exhaustive and the estimates that you will obtain for the association between the exposure or intervention and the outcome are based on the subset of evidence that you have identified and define or estimate the true association. This is the concept of fixed effects meta analysis \cite{hunter2000fixed} . Alternatively, you can conceptualise that the studies that you have identified for this meta analysis constitute a sample that is part of a larger population of studies. That said, this subset of studies from that larger population is interchangeable with any other study in that wider population. Hence this set of studies is just a random sample of all possible studies. This is the notion of random effects meta analysis \cite{hunter2000fixed} . So, are the studies very similar or homogeneous in the scope of the intervention or population, or outcomes? Therefore, it is important that when we conduct a meta-analysis, because if the studies are so different from each other that it is impossible to pool the results together, then we will have to abandon any notion of pooling the study findings to arrive at a summary estimate. If the findings are close enough then the studies are homogeneous and we would conclude that it would be OK to pool the study results together using what is referred to as fixed effects meta analysis. If on the other hand, we see that the studies are different by way of their results but nevertheless there are other areas (selection of the population, the intervention, and the outcomes) that are sufficiently uniform, then we can combine the results of the studies themselves but we may conclude that the apparent lack of homogeneity would arise as these studies are part of a larger wider population of all possible studies and hence we would rather report a random effects meta analysis.We will discuss two ways to measure heterogeneity of the studies. One way to test for heterogeneity is to use a statistic referred to as Cochran’s Q statistic. The Q statistic is a chi-square statistic. The assumption here is that the studies are all from the same "population" and therefore homogeneous and therefore a fixed-effects meta-analysis would be an appropriate measure to express the summary findings. Accordingly, the software first estimates a fixed-effects summary estimate. The fixed effects summary estimate is a sum of the weighted effect size. The weight of each study is determined by the variance of the effect estimate. Then, the sum of squared difference between the summary estimate and each individual estimate would have a chi-squared distribution with K-1 degrees of freedom where K = number of studies. If the chi-square value would be low, this would indicate that the studies were indeed homogeneous, otherwise, it would indicate that the studies are heterogeneous. If the studies are found to be statistically heterogeneous, the next step for you would be to test whether there are real reasons for them to be heterogeneous, i.e., the population, the intervention, and the outcomes are very different from each other. If this indeed would be the case, then, you would summarise the study findings as you would with a systematic review. On the other hand, if you find that the studies are otherwise similar, but perhaps one or more studies were to drag the summary estimate to one direction rather than another, you would assume while the studies are not homogeneous, they may be based on a larger pool of studies. Hence you may conduct a random effect meta analysis.Another measure of heterogeneity or statistical heterogeneity for meta analyses is \(\$I^{\left\{2\right\}}\) estimate. I^2 estimate is derived from another related estimate referred to as H^2, and H^2 is given by: H^2 = Q / K - 1 where K is the number of studies. Then, if Q > K - 1, then I^2 is defined as (H^2 - 1)/H^2; otherwise I^2 is given a value of 0. For example, let’s say are working with 10 studies, and the Q statistic is 36 (this will mean that the weighted sum of squared differences between the estimated fixed effect size and the individual effect size estimates in this case is 36); As Q > 9 for 10 studies (K = 10), therefore I^2 will be defined as 3/4 or 75%. On the other hand, imagine Q was 36 but this time based on 19 studies, so H^2 would be 2, and correspondingly even though Q is still greater than K-1 that is 18, I^2 would now be 50% (1/2); If the number of studies were more, say 25, then Q would still be higher than 24, but H^2 would now be 36/24 or 1.5, and I^2 would come down to something like 33% (0.5/1.5). A high I-squared statistic would mean gross heterogeneity while a low I-squared value would mean homogeneity (usually set at 30%)Step VII: Estimate summary effect estimateFirst, we shall determine the summary effect estimate assuming both fixed and random effects modelSecond, we shall construct a Forest Plot to visually inspect how the effect estimates of each individual study are distributed around a null value but also around the overall effect estimates.Fixed and random effects models refer to the two assumptions: fixed effects model assume that the populations on which these studies are based are uniform enough to determine that these set of studies are sufficient to draw conclusions about the relationship between the exposure and the outcome; random effects model assume that while we can relax the assumption that the populations from where the studies arose were same and therefore these sets of studies were sufficient to draw our conclusions, the studies themselves form part of an interchangeable body of evidence.