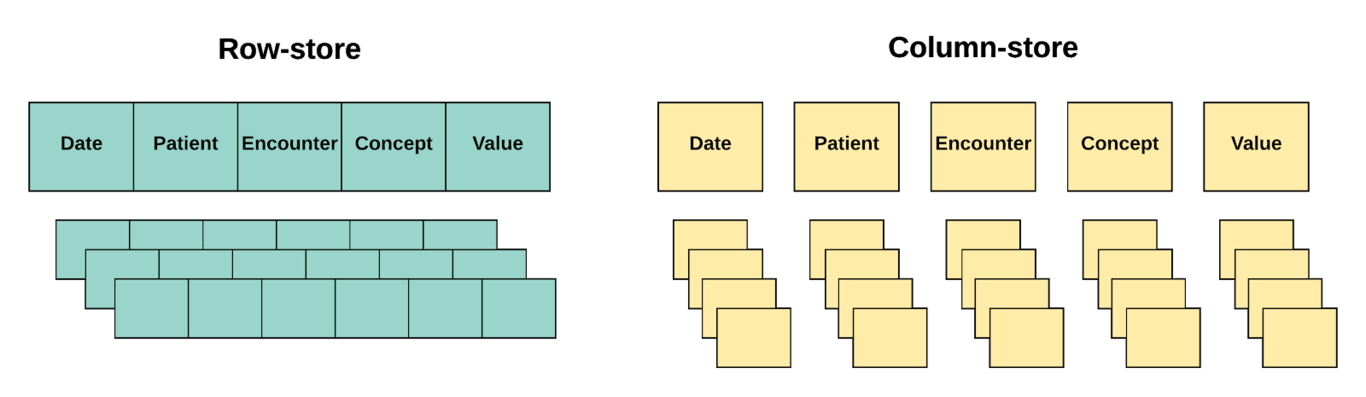
Background My internship at The Hyve is focused on addressing the performance issues encountered with data analysis of big observational health data (OHD) and analytical type (OLAP) workloads (e.g. “give me all the patients that smoke and have high blood pressure readings”) composed of healthcare relevant aggregation queries. Current implementations use traditional relational database management systems (RDBMS) to store OHD. An example use case is tranSMART \cite{athey2013transmart} which uses PostgreSQL \cite{database} as the main DBMS. The data is normalized in these systems; instead of having repeated data in a flat database, separate database tables are created to store this data and a key links it back to the main table. In terms of physical storage, all attributes of a record are stored contiguously on the disk. Under RDBMS there is both OLTP (Online Transaction Processing) and OLAP (Online Analytical Processing). In general, OLTP workloads are characterized by vast numbers of simple transactional SQL processes (INSERT, DELETE, UPDATE). The main focus lies on quick processing of queries and managing data integrity. RDBMSs effectively perform OLTP-style processes in high throughput due to the row store architecture. On the other hand, OLAP processes are defined by complex ad-hoc queries involving aggregations and a rather low number of transactions.