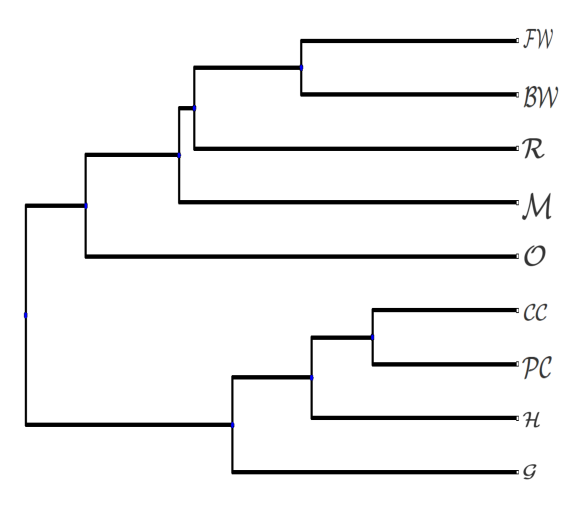
Comparison of protein sequence similarity is a significant study. By virtue of this method, we can expose the evolutionary relationship among protein sequences. So, it is required to design effective computational algorithms that can compare the similarities among the colossal amount of sequences. The aim of this research is to develop efficient tools in the field of protein sequences comparison and phylogenetic study. The proposed method performs a feature generation process based on the physio-chemical properties of amino acids that best describes the revolutionary relationship among the species in a protein family. The protein sequences are transferred into an Eighty dimensional feature vector among the group of amino acids. Finally, four different datasets were used to validate the accuracy of the proposal and a correlation coefficient of 0.94417 of ND5 dataset using ClustalW has been found. This is much higher than some of the methods. At last the result explains the effectiveness in the similarity analysis among genome sequences.