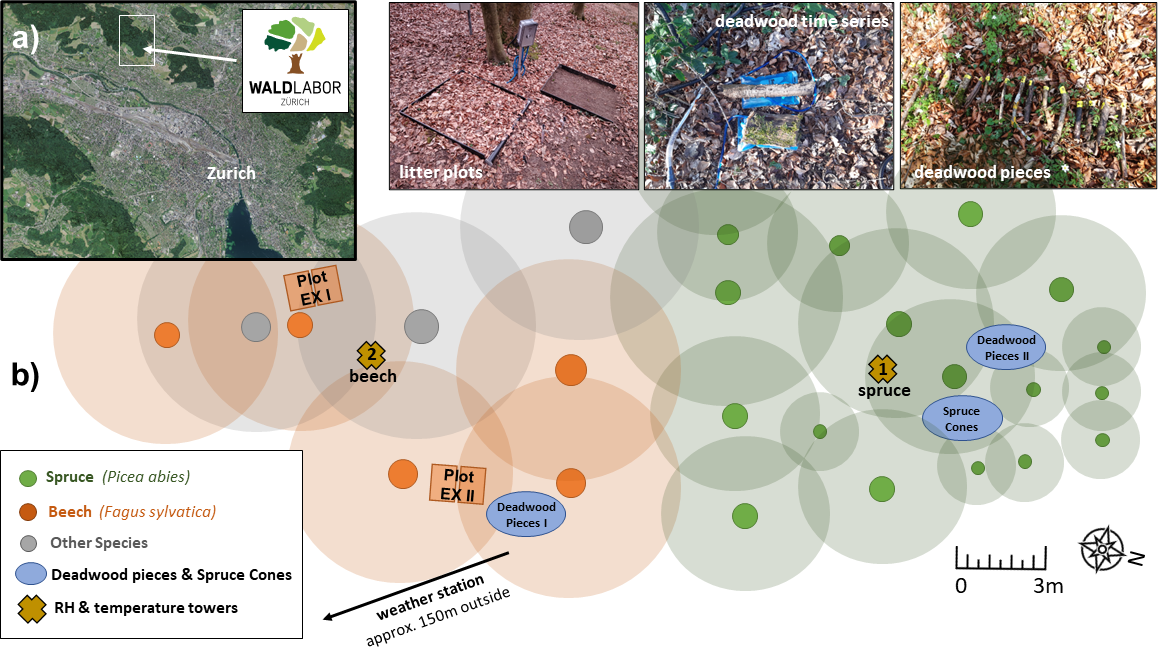
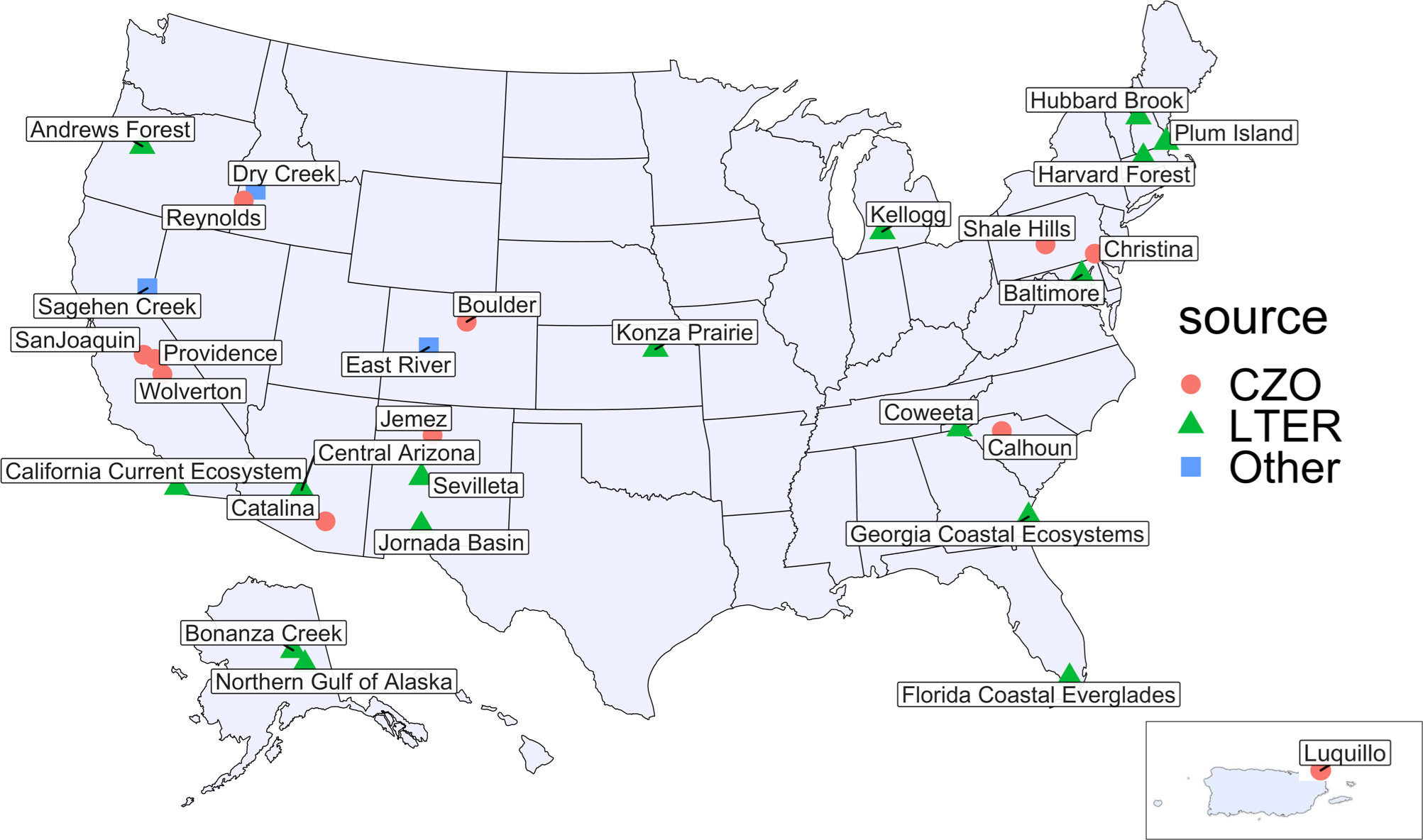
Hydrological analyses and their associated uncertainties are a function of their supporting observational datasets. Publicly available large-sample hydrology datasets covering a range of climates, times, and locations can be used to support inter-watershed comparisons, pattern identification, and watershed regionalization studies. However, most of the large-sample datasets are limited to a series of basic measurements such as precipitation, air temperature, and streamflow. Here we synthesized data from 30 intensively monitored catchments with soil moisture, snowmelt, and other hydrometeorological observations at daily scale across the US. This data synthesis product, CHOSEN (CONUS/Comprehensive Hydrologic Observatory SEnsor Network), includes watersheds from the Long-Term Ecological Research (LTER) and Critical Zone Observatory (CZO) networks, and several other ecological and hydrological observatories. Catchments span diverse climate gradients and encompass multiple biomes and ecosystems. To achieve a consistent and standardized data product, we first implemented data cleaning and control procedures with strict variable naming conventions and unit conversions. Following data quality control, data processing methods, including gap filling by interpolation, linear regression, and climate catalog-based techniques, were implemented to produce alternative level-2 products. The data and metadata were written into self-describing NetCDF files, facilitating ease of access by multiple computer platforms. All python coding scripts, ranging from processing to accessing the NetCDF files, are publicly available, along with a user-friendly tutorial. The standardizations adopted here, and the availability of the data-processing pipeline, will facilitate future additions of new observations to this database. We anticipate that this synthesis will support comparative long-term hydrological studies and contribute to a growing body of open-source research in watershed and ecosystem science.