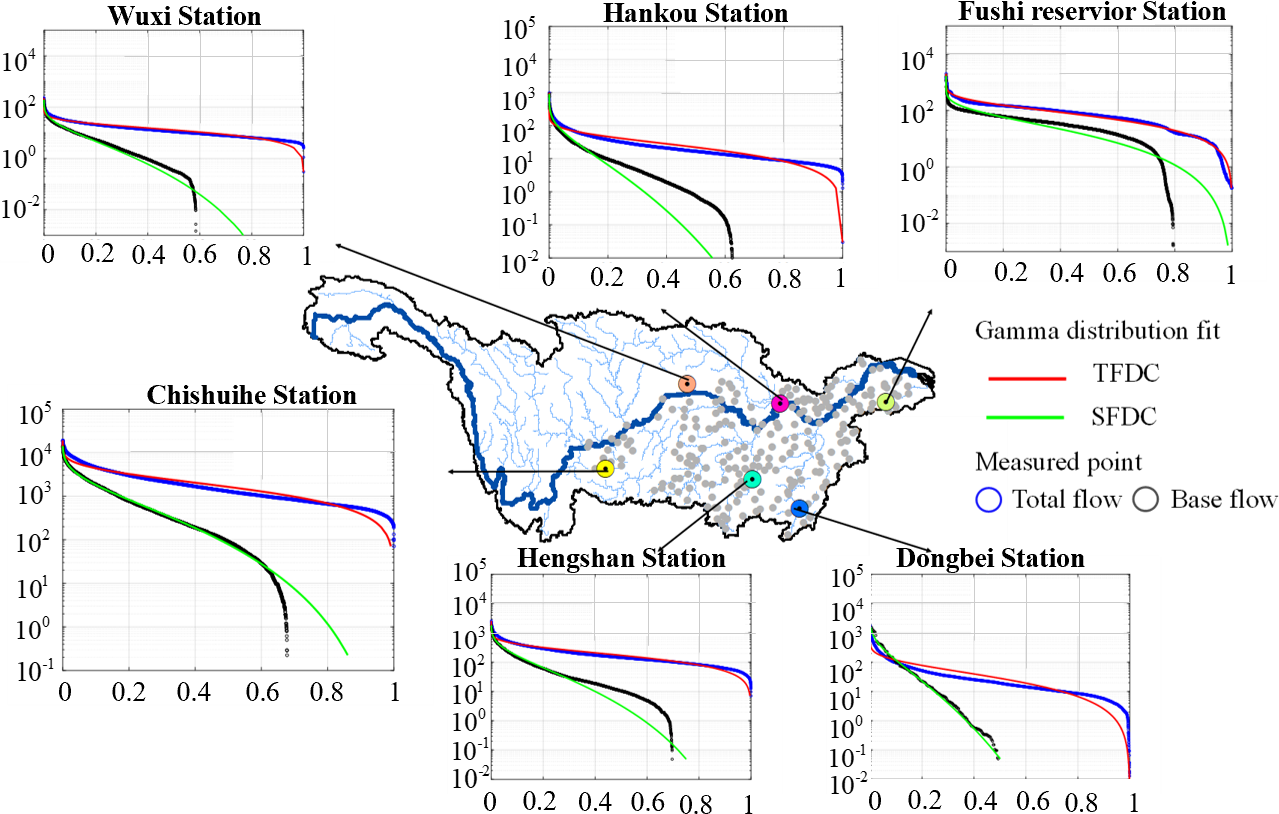
This paper aims to solve the problem of accurately estimating flow duration curves (FDC) in catchments lacking diachronic flow data. Based on 645 sets of observed data in the middle and lower reaches of the Yangtze River (YZR), which include 22 basin characteristic variables, eight machine learning (ML) models (SVM, RF, BPNN, ELM, XGB, RBF, PSO-BP, GWO-BP) were integrated to predict the FDC (quantiles of flow rate corresponding to 15 exceedance probabilities were studied), after which the model most suitable for predicting was determined. Finally, the SHapley Additive exPlanation (SHAP) method was used to determine and quantify the impact of various input variables on different quantiles and the degree of that influence. Results indicate that: (1) The GWO-BP model is the best ML model for predicting FDC among the eight, having good prediction performances throughout the entire duration with determination coefficients (R2) on the testing set of 0.86 to 0.94 and Nash-Sutcliff criterion (NSE) of 0.78 to 0.94. (2) The ML model (BPNN) optimized using swarm intelligence can effectively predict FDC. (3) The predictive impact of variables on different quantiles varies, with and BFI_mean contributes significantly to predicting FDC. The former has a negative effect on the prediction result and has better contribution to predicting higher flow rate (i.e., having higher accuracy in predicting the upper tail of FDC), whereas the latter is the opposite. SHAP’s explanations are consistent with the physical model, revealing local interactions between predictive factors. The results demonstrate that the method proposed in this paper can greatly improve the prediction accuracy and is innovative and valuable in model interpretation and factor selection.