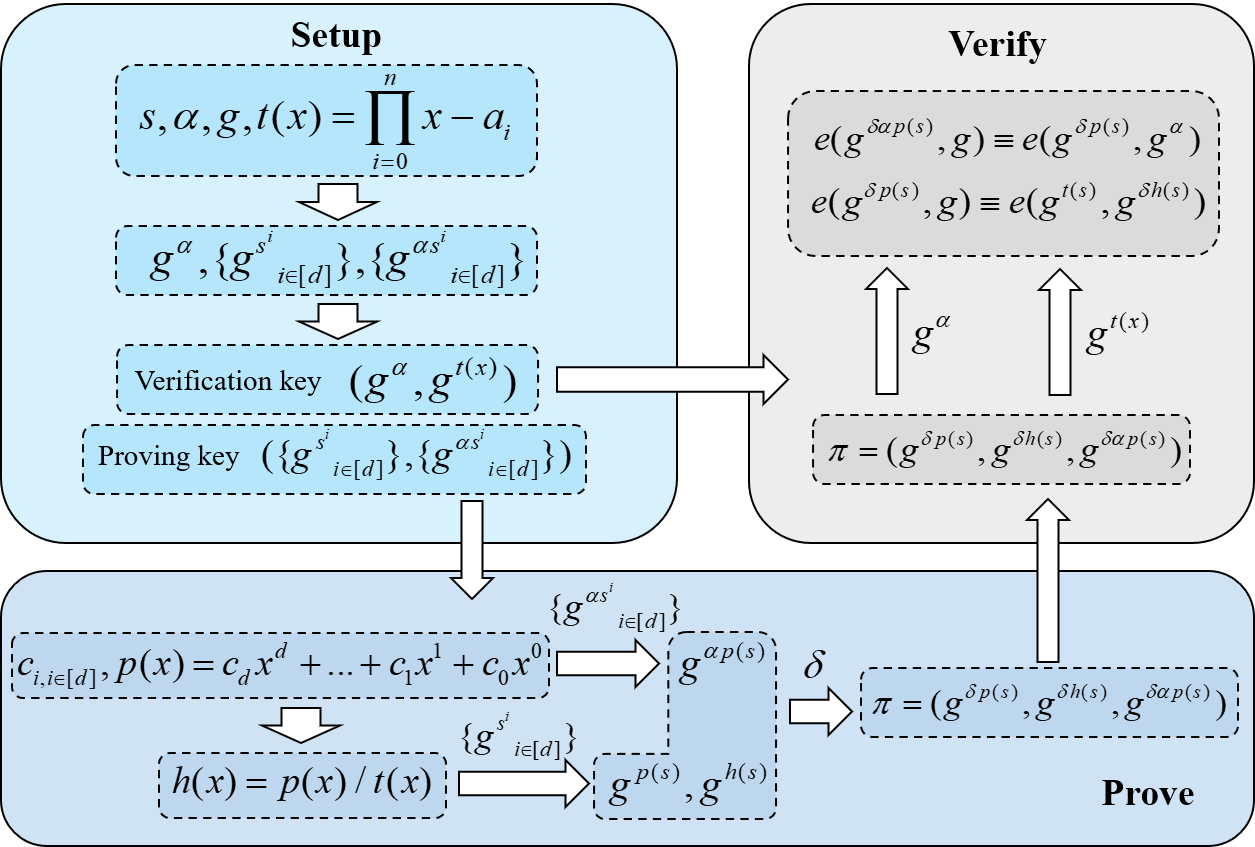
Zk-SNARK unleashes the great potential of ZKP (zero-knowledge proof) in the blockchain, distributed storage, etc. However, the proof-generation of zk-SNARK is excessively time intensive, making it a challenge to deploy a high-performance zk-SNARK in most real applications. As a result, NTT (Number Theoretic Transform), one of the most time-consuming parts in proof-generation, needs to be accelerated significantly. To address this issue, we propose a novel and efficient “data reordering” technique to enable a highly pipelined architecture, on which an FPGA-based hardware accelerator is designed to support the large-bitwidth and large-scale NTT tasks in zk-SNARK. Our architecture achieves a two-level pipeline: 1) the top-level pipeline is achieved among smaller NTT sub-tasks, which are decomposed from a large-scale NTT task; 2) the bottom-level pipeline is achieved in each sub-task, among butterfly operations with different step sizes. This architecture can effectively reduce the data dependency and memory access requirements, meanwhile, can be flexibly scaled to different scales of FPGAs. To balance computing efficiency and flexibility, the OpenCL equipped with HLS is used to implement the heterogeneous acceleration system. We prototype the accelerator on the AMD-Xilinx Alveo U50 card (UltraScale+ XCU50 FPGA). The evaluation results show that 1) our accelerator shows high scalability for different scales of FPGAs with a stable performance improvement; 2) it performs 1.95× faster than the one in PipeZK; 3) and it achieves 27.98×, 1.74× speedup and 6.9×, 6× energy efficiency improvement than AMD Ryzen 9 5900X single core and 12 cores respectively when integrated into the well-known ZKP open-source project, Bellman.