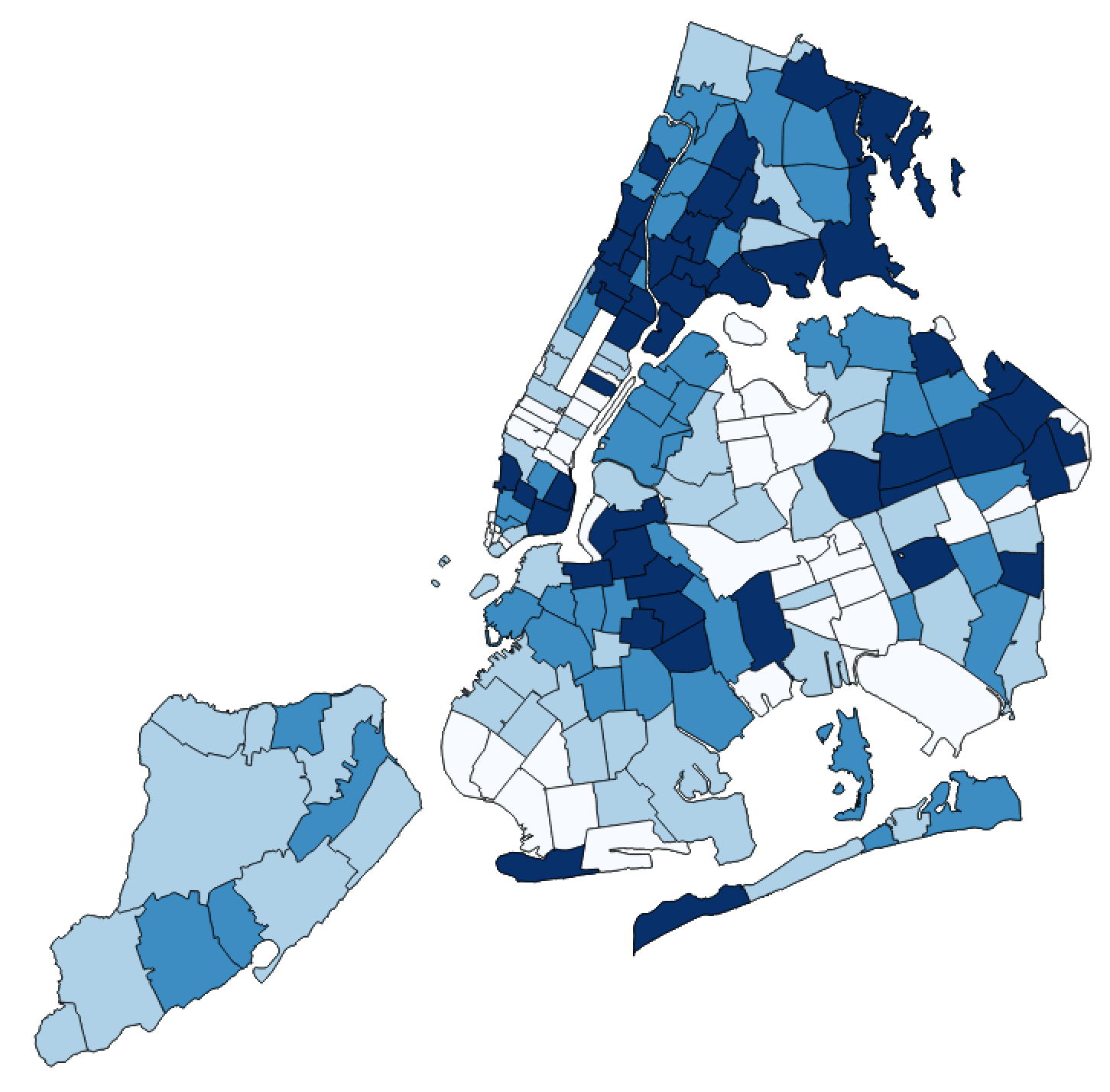
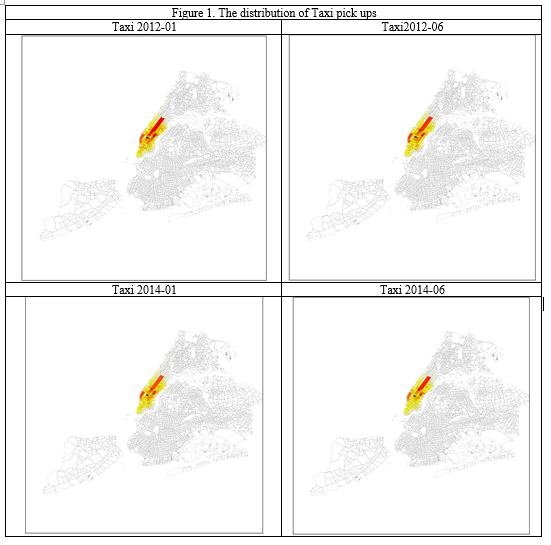
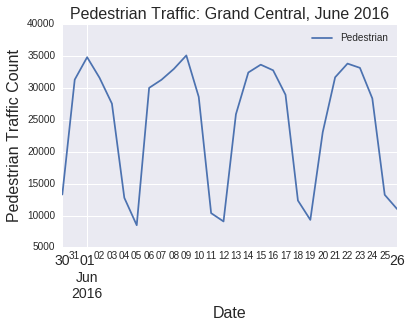
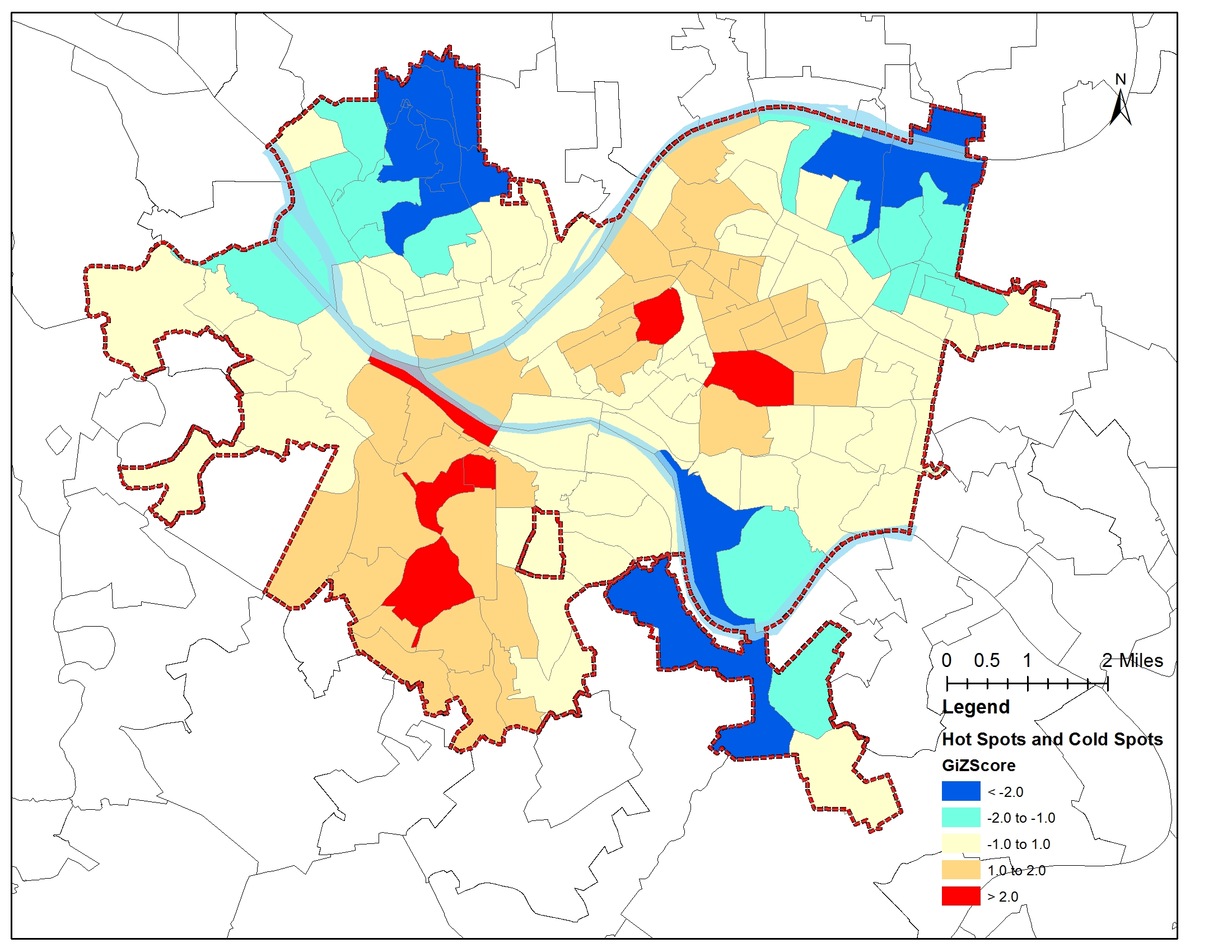
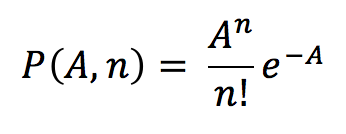Pooneh Famili pf910 Github: poonehfamiliAbstract: This research project seeks to find the impact of the socioeconomic factors (age, income), city facility (proximity to subway station), and safety score of the streets on the taxi trips rate at census tract level. I used multivariate regression technique for analyzing the data. The result indicates that the most important factor that affect the popularity of taxi in an area is the median income of the neighborhood. Also, there is a significant negative correlation between distance to subway and age with the number of Taxi pick-ups, as well. Key words: Taxi pickup numbers, socioeconomic factors, Multivariate regression, NYC Introduction: The question that this study seeks to find an answer to it is: “How much socioeconomic s’ indices and city facilities can have impact on the popularity of Taxi at the neighborhood level in NYC”. This question could be important since it could help the Taxi agencies and transportation organizations to plan more effectively, Taxi drivers could find out in which neighborhoods the chance of having more trips are higher, and also gives a good view regarding the difference between the Taxi pickups and its today’s main competitor: Uber.To doing so, first I picked four indices to do analysis on them, median age, income of the neighborhood, the distance from subway station, and the safety score of the street. Then after data wrangling and cleaning data I have done multivariate regression on my data to find out the correlation between each of above factors and the number of pickups. Data: In the data collection phase, first I got the data for all Taxi trips of one month in summer (June) and one in winter(January) for the Taxi in 2012 and 2014 from https://github.com/toddwschneider/nyc-taxi-data/blob/master/raw_data_urls.txt. Since the data for Uber is just available from April 2014 I used the data for June 2014 to be comparable with taxi trips from https://github.com/fivethirtyeight/uber-tlc-foil-response/tree/master/uber-trip-data.Regarding socioeconomic metrics, I used median age and income data from http://nyu.policymap.com/ which are available at census tract level for 2010. For accessibility, I got the data of subway locations all over the NYC from https://data.ny.gov/Transportation/NYC-Transit-Subway-Entrance-And-Exit-Data/i9wp-a4ja/data. Finally, for safety issue, I used the safety score of NYC streets (which is available in the link below).The data for safety scores include points that are not even at intersections, in order to get the safety of the taxi pickup points, I calculated the distance between each point and all city safety scores then for each point I selected the one which is closest to it. This is the strategy that I used to find the proximity of each point from subway stations. For age and median income, some of the census tracts have more than one attributes. Since I couldn’t find any documents attached to find the reason behind that I got the average of them and replace that for their age or income. All the data sets for Taxi include more than 10million trips (mean15 million for 2012 and 13,800,000 for 2014), and for Uber (700,000trips reported). To be able to do the computing process on it I picked 20000 randomly from each of them.As mentioned above the data for subway and safety score include points (lat, lon) as their coordinate and I found and merged them on the common points to the data frame which I was working as the main data set. Since I wanted to do my analysis at the level of census tract I found the intersection of all point with the census tracts, I grouped my data by that and got the mean of the point attributes in each census tract and used.Then I merged data of age and income which were available at census tract with my data set.Since I wanted to do multivariate regression analysis on my data sets, I normalized all my four features.Some of the (less than 10 in all of the datasets) are null which I dropped.I did all the above steps in the separate notebook for each data sets for taxi and Uber and saved the result data frame in csv format to use it in the “analysis notebook”.All the notebooks are available at the link below.In comparison phase, I also merged the related datasets.To get a good understanding from my data I calculated the number of pickups in each census tract, and added it to my data and mapped the frequency of pickups for each census tracts(Figure1&2). The maps show that all my data are from Manhattan. Then this research just can be applied for Manhattan. Methodology: This research used multivariate regression technique to find the correlation between each of the independent variables and the frequency of trips at the census tract level. Since these variables are independent of each other, multivariate regression works for our purpose. This method has been used in several studies that evaluate the coefficient correlation of an independent variable with the dependent one. In the ADS class, we had a real world example that evaluates the impact of the different factors such as income of the residents, the size of the units on the price of the buildings, and multivariate regression technique was used. This method cannot eliminate the multicolinearity between the dependent variables, which PCA doesn’t have this problem, and if we had more available datasets it would be the better option. Conclusions: Findings:The analysis from taxi 2014, January data that has been done through multivariate regression indicates that income, age and distance to subway have significant coefficient correlation with the number of taxi pickups (Pvalue: 0, 0.02, 0.008(all of them smaller than 0.05)), their coefficients are (221, -72, -51), R^2 = 0.241 (Figure 3, 4, 5, 6,7)The other four data sets also have the same trend, except taxi 2012 June, and Uber 2014 June that their distance to subway has p value greater than 0.5. Interpretation:My findings show that, disrespect to the time differences (2012 or 2014, winter or summer) of the datasets income is the most important factor that have positive coefficient correlation with taxi pick up in Manhattan. Also age, and distance from subway station have negative impact in all of my analysis that make sense since the far you are from subway, the more is the probability to tend to take the Taxi, and as you are more aged you have more money to take the taxi and less energy to walk.Based on the maps (Figure 1,2), the other interesting result is that the most popular point for taxi is in the midtown around Times Sq, which is tourist attraction spot, but for Uber is in midtown west which is poor regarding public transportation, but there is no tourist attraction in that area (mostly stores, and vehicle stores), that confirms the previous study on this subject (newsroom.uber.com), that claims most of the Uber trips are destined to transportation hubs.However, I got the same number of trip from all my data sets, 20000, but all of them not distributed equally regarding the most popular census area, for example for Uber 2014 June and Taxi in the same time, the top popular census tracts are different(Figure9), and also from winter to summer these spots are different even for only the Taxi (Figure 8). Future work: If we could add more independent variable to our model like the number of site seeing, the number of people above 18 instead of average age of all people, the number of building units in census tract(density), and use PCA to eliminate the multicolinearity that would give us the important factors with more certainty. Also, if we would run special analysis to find the autocorrelation between the census tract taxi trips rate or clustering the census tracts by their Taxi trips rate, it would give us interesting result. Finding the exact characteristics of census tracts which are significantly different regarding their pickup numbers, for Uber or Taxi, or just Taxi in different times of the year could help us to get a better understanding of reasons behind that. Links: To make my code reproducible, I have put all my data sets on the Github:https://github.com/poonehfamili/PUI2016_pf910/tree/master/extra%20credit Bibliography: http://toddwschneider.com/posts/taxi-uber-lyft-usage-new-york-city/https://newsroom.uber.com/us-new-york/top-destinations-in-nyc-according-to-the-data/https://data.ny.gov/Transportation/NYC-Transit-Subway-Entrance-And-Exit-Data/i9wp-a4ja/datahttps://github.com/fivethirtyeight/uber-tlc-foil-response/tree/master/uber-trip-datahttps://github.com/toddwschneider/nyc-taxi-data/blob/master/raw_data_urls.txthttp://nyu.policymap.com/ Appendix: