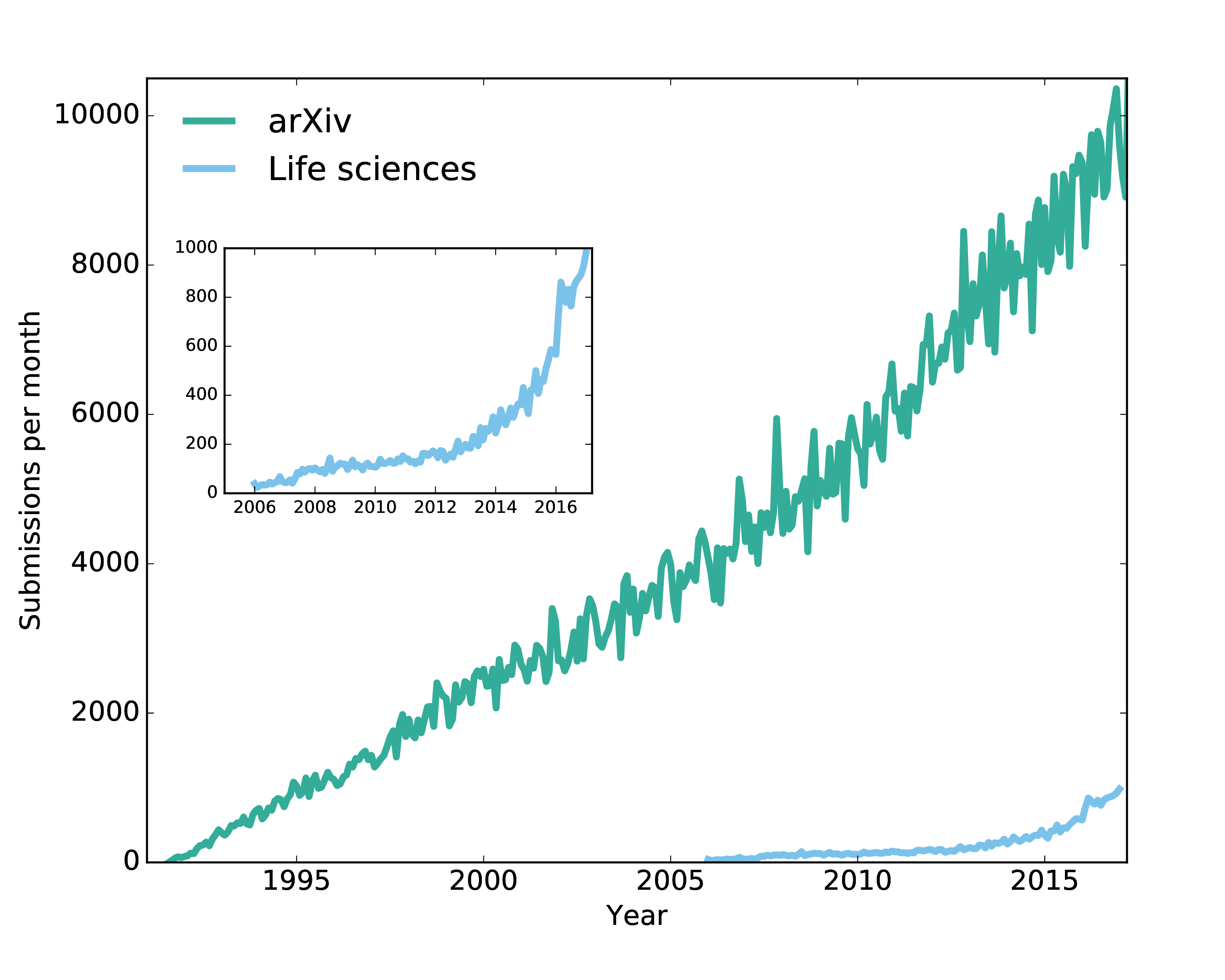
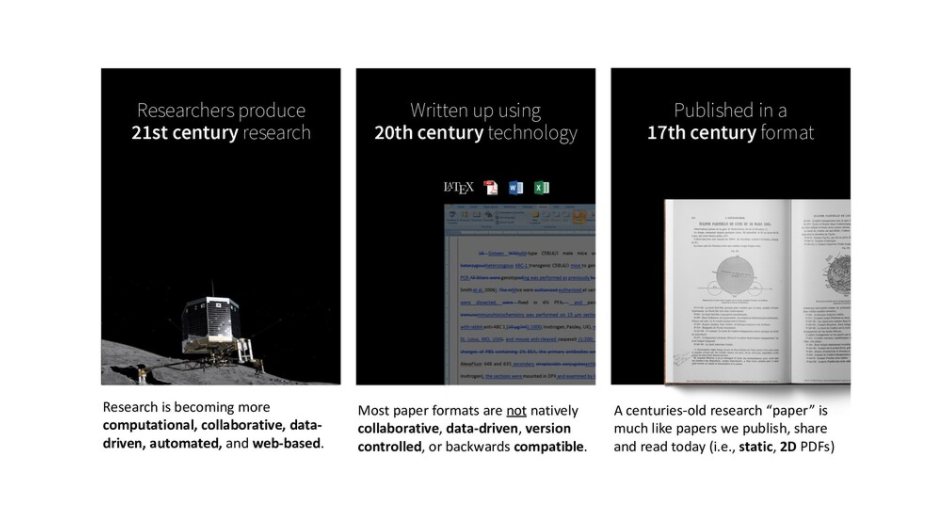
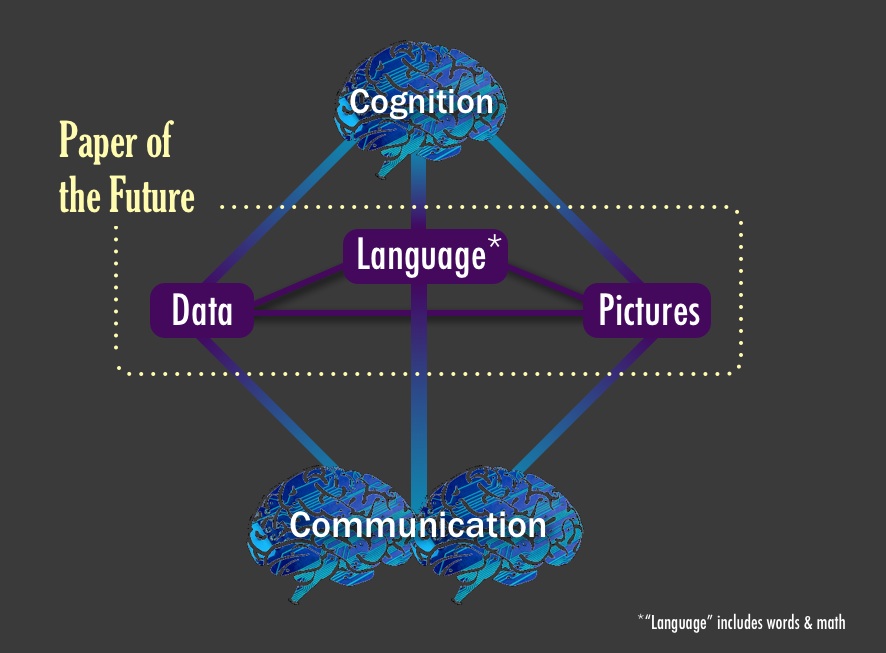
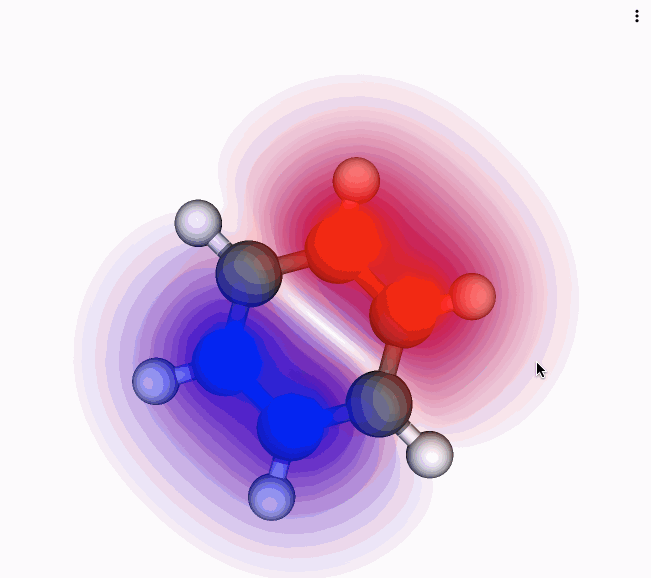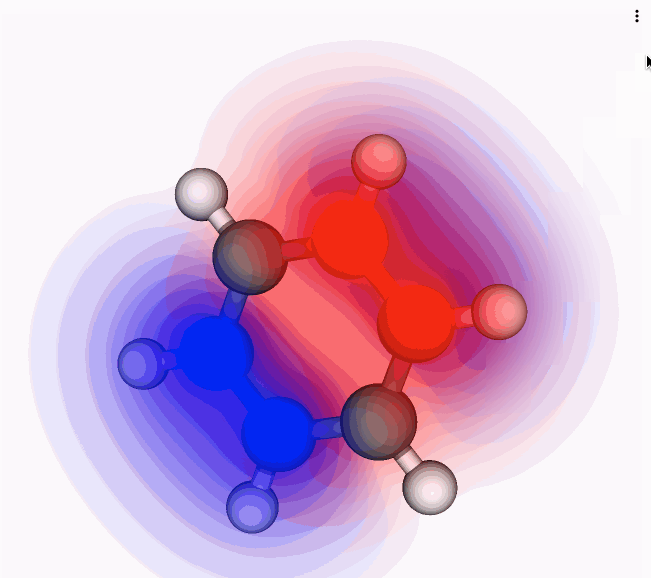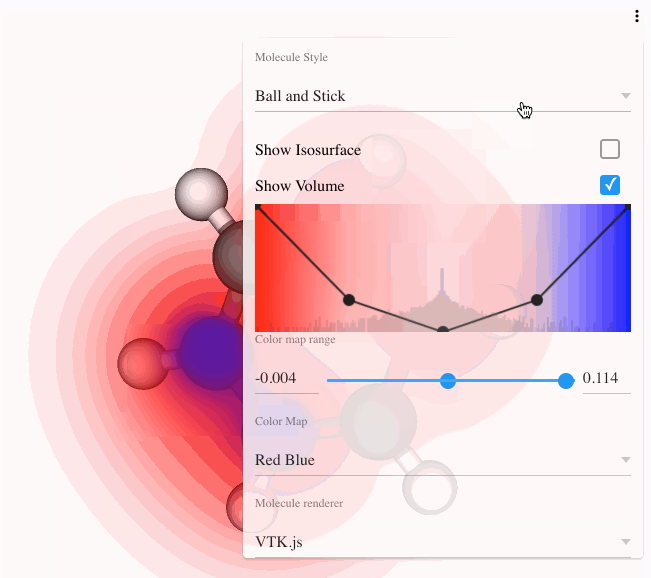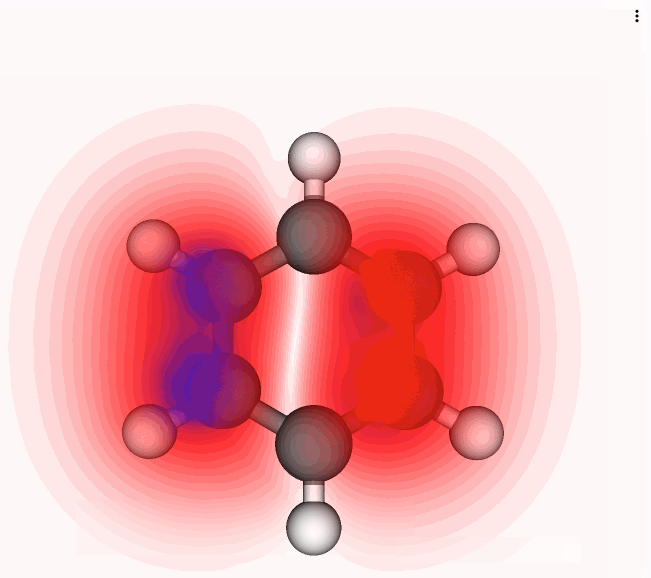
Why are scientific ideas disseminated via "papers"? Is a paper the best way to share and publish research results today? The format and function of research communication has not changed much in the last 400 years. Take any paper published this week, download it, and compare it to a digitized version of a paper from the 1600s. The two papers may differ in page layout, color, and typeface, but they are essentially identical in format - a collection of text and figures. Indeed, the fact that we refer to the mainstream outlet of research communication as "paper" speaks volume of its boundness to print.While the published format has not changed in the last 400 years, the change in published content is astronomical: a proclamation of the success of science. The discovery of molecular structure of DNA \cite{WATSON_1953}, penicillin \cite{Fleming1980}, and the formulation of general relativity \cite{Einstein_1916} are some of the biggest and most splendid scientific discoveries of all time. They were all published in a two-dimensional paper format. Even more recently, the groundbreaking discovery of gravitational waves, which earned the 2017 Nobel Prize in Physics to the leads of the LIGO collaboration, was published with a traditional paper format \cite{Abbott_2016}. LIGO's groundbreaking was certainly not analyzed on a 2D piece of paper.So, how is it possible that scientists produce and write cutting-edge "21st-century research" and still publish it in a "17th-century format"? \cite{obsolete,Pepe}Obviously, the paper format, being so enduring and persistent, has served science well. But things have changed in the last three decades. The recent explosion of content digitalization, growing internet speed and connectivity, and reliance on data, code, and computational power are leading to an unprecedented and irreversible path to changing the way we publish and disseminate research ideas. A Gutenberg-style revolution in scholarly communication is upon us, and we believe it is being pioneered by the Open Science movement. The Open Science initiative aims to make scientific research and its dissemination accessible, reproducible, and transparent. In addition to encouraging publication of research as Open Access as early as possible (the availability of preprints in subject-based repositories has moved beyond the realm of physics), for many computational domains Open Science translates into making code and data available to everyone, and into practicing "open notebook" science. In other words: readers and reviewers must be able to understand how the authors produced the computational results, which parameters were used for the analysis, and how manipulations to these parameters affect the results. Increasingly, journals and funding agencies are mandating that researchers share their code and data when reporting on computational results based on code and data. However, even when data and code are provided by authors, and published, they are oftentimes relegated to Supplementary Information or to entirely separate platforms, disconnected from the published "full text". Since code, data, and text are not linked on a deep level, readers and reviewers are faced with barriers that hinder their ability to understand and retrace how the authors achieved a specific result. In addition, while data and code may be available in repositories external to the corresponding article \cite{Antoniol_2002}, it takes readers and reviewers considerable effort to verify the software and re-run analyses with, say, changed parameters.The idea of a multimedia, multi-dimensional, scholarly publication that defies the limitations of the 2-dimensional paper format is not new. The publication history of the first detection of gravitational waves by the LIGO collaboration is an example of how much this is needed in scientific publishing. The discovery was reported in a series of traditional articles \cite{Abbott_2016}\cite{Abbott_2016a} but with an associated and externally hosted supplemental Jupyter notebook \cite{losc-tutoriallosc_event_tutorialmaster}. The notebook allows readers to run and tweak the code, change parameters to alter the analysis, and, in its section dedicated to the signal processing of the gravitational waves into sound, it even allows readers to play the bloop of two black holes colliding. Yet, the notebook and the multimedia elements had to reside outside the article. Why?