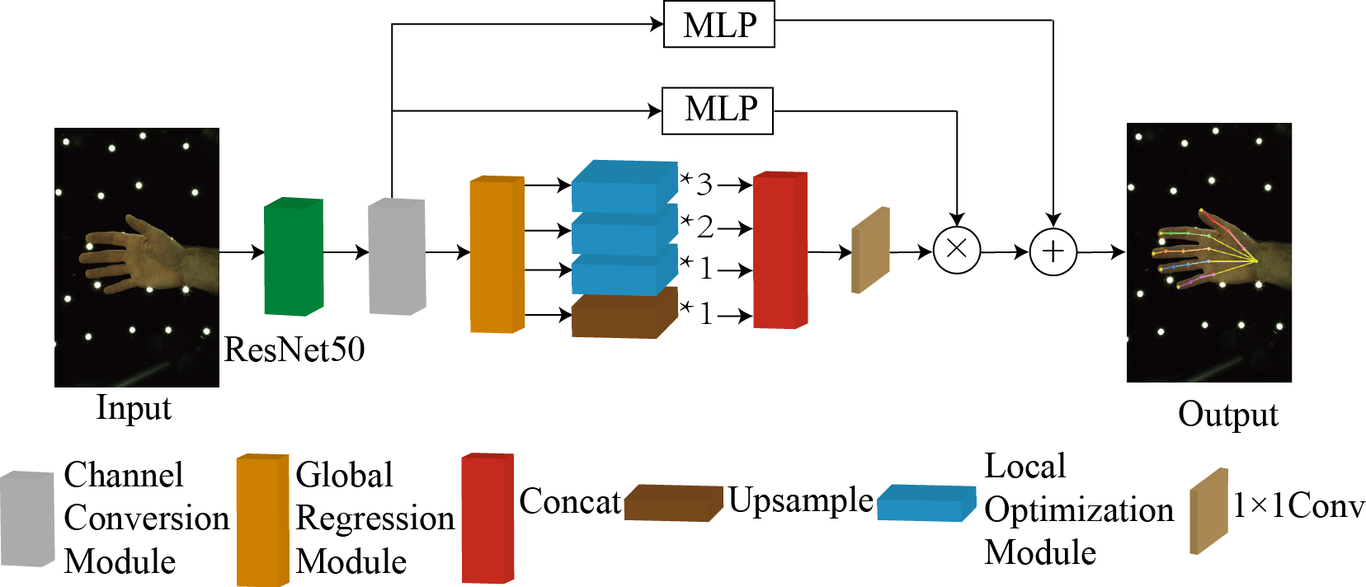
Hand pose estimation based on a single RGB image has low accuracy due to the complexity of the pose, local self-similarity of finger features, and occlusion. A multiscale feature fusion network (MS-FF) for monocular vision gesture pose estimation is proposed to address this problem. The network can take full advantage of different channel information to enhance important gesture information, and it can simultaneously extract features from feature maps of different resolutions to obtain as much detailed feature information and deep semantic information as possible. The feature maps are merged to obtain the hand pose results. The InterHand2.6M dataset and Rendered Handpose Dataset (RHD) are used to train the MS-FF. Compared with the other methods (which can estimate interacting hand poses from a single RGB image), the MS-FF obtains the smallest average error of hand joints on RHD, verifying its effectiveness.